上一期我们讲到了瀚思科技流引擎团队成员吴昊,王唯在刚刚结束的 Flink Forward Europe 2019 大会上的见闻和关于如何利用Flink SQL来构建整套自动化机器学习流程的精彩分享。还没有阅读过上一期内容的小伙伴,请从以下入口开始阅读:FaaS + AI + 统一计算模型 —— Flink Forward Europe 2019 会议之行回顾。也可以点击以下视频收看现场吴昊、王唯同学在柏林演讲的完整视频。
本期,我们将具体介绍瀚思在整合机器学习算法方面的设计,以及基于Flink SQL 构建自动化机器学习流程的相关实践。整合自动化机器学习的 HQL(HanSight Query Language®️)是瀚思全场景安全平台对外提供的关键能力。如果您对全场景安全平台概念还很陌生,请猛戳以下链接,获取一手资料:《全场景安全赋能数字化转型》白皮书。
简单地说,全场景平台是在安全运营平台上,提供对传统网络安全、账号安全、数据安全、业务安全等企业内部安全问题的检测与响应能力。全场景自然要求检测能力要覆盖各种方法,包括特征、流处理规则、算法等,而且各种方法的用户体验需要一致。HQL被设计为一种多段落的简洁脚本语言,兼容 SQL语言,同时借鉴了最新的 Python Notebook 的界面,提供了一套编程环境,这样不管运行时是离线还是在线分析模式,使用什么分析方法,对外的用法都一致,且非常容易共享。
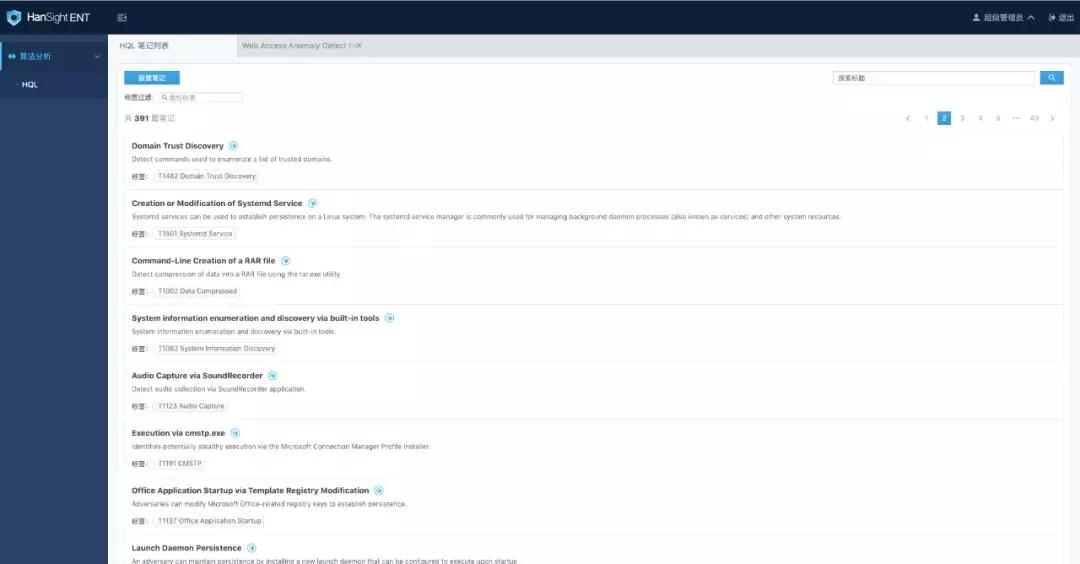
图1. 全场景平台预置的 HQL,大多已经 ATT&CK 标签化
接下来,我们将从以下几个要点探讨如何利用机器学习为产品赋能:
在客户场景中遇到的主要问题;
在流计算应用中引入机器学习算法的挑战;
如何利用Flink SQL构建自动化机器学习流程。
在客户场景中遇到的主要问题
主要问题体现在三个层面:
1、商业需求
2、场景建设
3、部署成本
首先需要明确全场景安全平台的商业需求:应对企业面临的日益增长的威胁,大致包括传统网络安全、账号安全、数据泄露、内部员工威胁、业务欺诈等等。各种问题对应的常见分析方法都不一样,重实效性的网络安全问题,大量使用实时流分析,账号安全和数据泄露需要对用户和资产进行长周期基线分析,而业务欺诈因为数据量大,业务变化快,需要短频快的进行各种聚类、分类算法分析。商业上需要一个平台同时提供这些性质截然不同的分析方法。
场景建设层面:POC阶段,我们提供开箱即用的标准场景,包括:企业合规类场景,预置异常检测场景,默认算法场景,以及网络安全Threat Hunting场景。
以上四大类场景中的每一个细分场景,如账号安全,文件访问,外设使用,数据库审计等,都有对应的数据源要求。这样做的好处在于不仅能够快速验证客户数据、出效果,同时能够体现专业性。当客户提出业务特有的场景需求时,尤其是需要定制算法时,我们可利用HQL算法平台,进行所见即所得的交互式开发。
部署层面:由于账号、数据和业务类安全分析会把各种类型的告警汇合以人或资产的维度做综合分析,故而对数据质量有较高的要求。需要数据积累在一个月以上,同时需要数据分布不能过于稀疏,否则底层的机器学习算法无法发挥作用。另外针对机器学习算法门槛高的问题,一个成熟的全场景安全产品需要提供出厂的易于使用的机器学习算法库,方便实施人员能够快速上手。这就对底层架构,算法整合,交互设计等各方面提出了极高的要求。
HQL内置多种标准机器学习算法,支持标准的整套机器学习算法流程,包括数据加载->ETL->特征工程->模型训练->模型验证->上线服务。同时提供强大的交互式界面,整套流程可以通过拖拽的方式即可完成,无需手写机器学习代码。
算法流程的技术工作主要包括:
对常用机器学习算法的本地化支持(时间序列,关联关系,聚类分析,决策树等),内置在Flink计算引擎之中
设计并实现来类似SQL语法的简单易用的HQL查询、分析语言,可完成SQL语法支持的常用查询、聚合、分析操作
将常用map/reduce方法,以及机器学习算法以UDF的形式集成在HQL算子中,可直接调用HQL内置方法关键字进行使用
自动化编排机器学习平台,对特征工程,模型训练、预测、验证,上线服务,运行状态监控等典型机器学习流程做了高度抽象
丰富的自动补全和内容提示,提高交互体验,降低学习成本
集成400+ ATT&CK techniques和tactics,同样以HQL内置场景的方式提供给用户,可直接调用进行网络安全场景的Threat Hunting
文档化200+各种类型安全场景,大大降低POC阶段部署成本
在流计算应用中引入机器学习算法的挑战
在实时计算流程中,流数据是实时的、海量的、易丢失的和无界的,因此在流计算中运用机器学习算法必须要能够处理好流数据的这些特性。流数据的实时性能够让我们快速发现安全威胁,从而争取响应时间,但是也带来了机器学习算法性能的挑战。流式数据同时也是海量的,往往无法在单台机器进行运算处理的,所以流式计算中的机器学习算法也必须支持分布式运算。
易失性是指流式数据中的数据一旦丢失就无法重新获取,而历史数据是机器学习算法中的重要部分,在系统无法同时加载所有历史数据时,历史数据的存储问题也是我们面临的挑战之一。而无界性则表示流式数据是源源不断无穷无尽的,系统如何处理历史数据和延迟数据,动态更新算法模型以适应新的数据也是一个挑战。
面对流式数据的海量性和实时性带来的性能问题,我们对部分常用机器学习算法进行了分布式处理。而为了应对流式数据的海量性和易失性,我们引入了 Feature Store 来存储特征工程的结果。经过调研,我们选择了 TimescaleDB 来存储特征信息。它默认以事件发生时间戳和分析的实体ID为索引来存储数据,支持每秒百万级特征存储和带时间范围的高性能批量特征读取。值得一提的是,在机器学习过程中往往特征工程比算法更耗时,Feature Store 技术能够避免重复进行特征工程计算,从而提升效率。为了及时处理历史数据,在算法中引入了衰减函数消除过于久远的历史数据对结果的影响。Flink 自带的 watermark 机制也能够较好处理延迟数据。通过 Flink SQL 的 UDF 功能,将算法实现封装在 HQL 语法中,从而简化机器学习任务构建流程,以便最大化的实现自动化编排。
如何利用Flink SQL构建自动化机器学习流程
在HQL中,可以通过简单的语法定义机器学习流程,如图1所示。
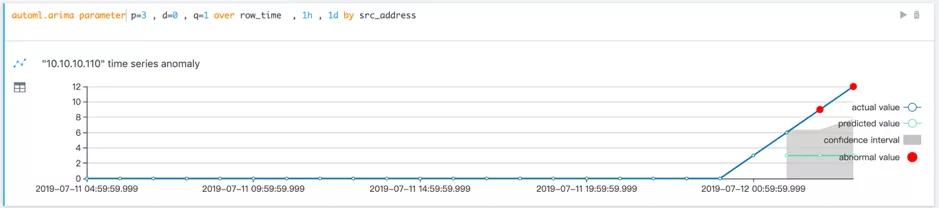
(a)
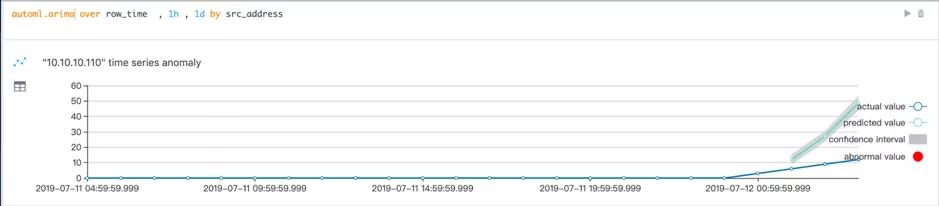
(b)
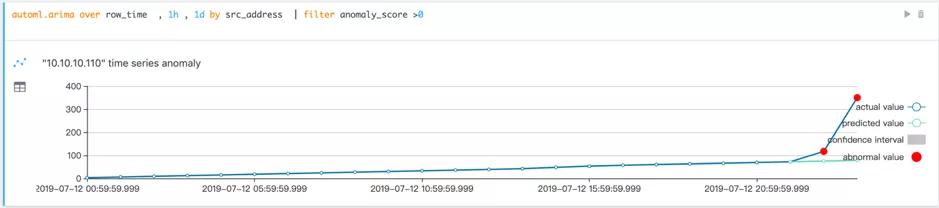
(c)
图2. ARIMA时间序列算法
在上图中,通过简单的一句 HQL 语法,指定分析对象,时间窗口和算法参数就可以执行 ARIMA 时间序列算法。在我们日常的安全分析中,由于分析对象的不同,其行为也不尽相同,用同一组参数分析所有用户可能会出现如图 (a) 中所示的分析不准确的情况,实际中也无法为每一个分析对象调参构建模型。因此HQL中加入了自动参数选择,对比图 (a) 和图 (b) 可以发现,通过自动参数选择获得的预测曲线更加准确合理。图(c) 展示了通过真正的异常情况,在最后两个点 IP”10.10.10.110” 的访问次数增高,增长速率也远远高于以往。
在 AutoML 中,可以更加简单的通过拖拽的交互方式配置一个机器学习任务。图2 中所示的是一个 XGBoost 模型训练任务。该任务流程为:加载数据源—>选择分析列—>Feature Store 特征工程—> K-means 聚类—>Xgboost 模型训练—>模型打分—>模型保存。最终运行结果,通过对比各个模型的打分结果,就可以选取最优模型。
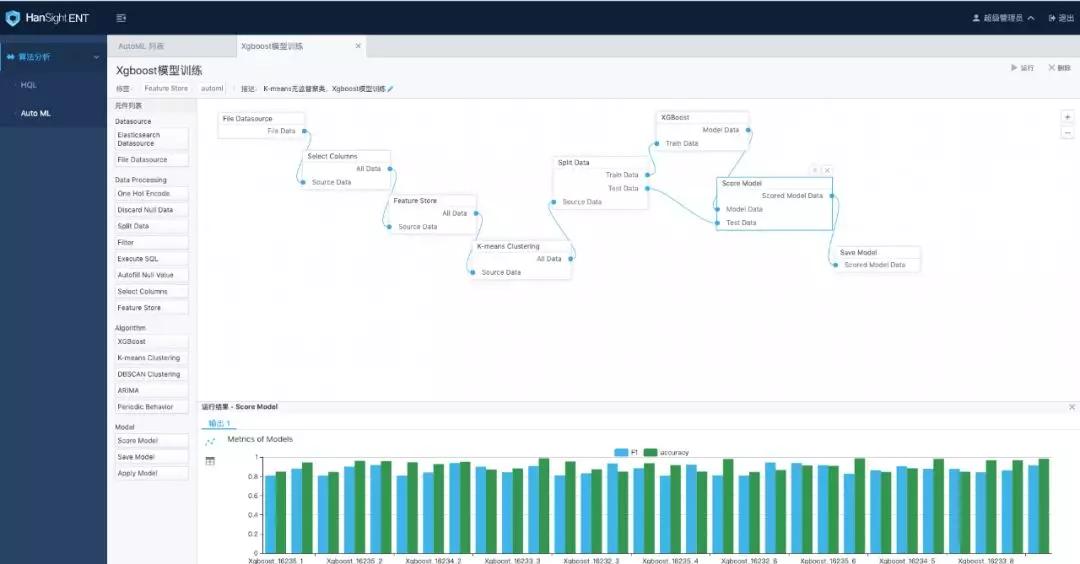
图3. XGBOOST 模型训练
瀚思全场景安全平台就是在这样一步一步摸索中逐渐成长起来,成为国内首屈一指的在异常检测,算法能力,产品集成以及可视化交互方面都拥有优异成绩的产品。
文章来源:网络 相关文章
相关文章



 精彩导读
精彩导读




 热门资讯
热门资讯 关注我们
关注我们
