语音识别是AI领域的一项重要基础服务,同样也是vivo AI体系中举足轻重的能力,是Jovi输入法、Jovi语音助手等应用的基石。打造高准确率、高性能的语音识别引擎,才能给vivo亿级的语音用户带来良好的体验。基于wenet端到端语音识别工具,vivo结合自身业务场景进行深度优化,成功研发离线和流式识别引擎,支撑vivo语音业务的快速发展。

随着用户量的快速增⻓,语音识别性能问题凸显,CPU推理方案在峰值场景TP99延时较高,且难以满足高算力的业务场景。为确保良好的用户体验、进一步提升产品及服务质量,性能优化、降本增效势在必行。
vivo AI工程中心在模型推理加速积累了多年经验,为此自研一套语音识别流式推理引擎。引擎支持动态batching、显存池、数据分桶排序等特性,同时支持CPU和GPU,并在GPU上取得了不错的加速效果。
昆仑芯科技深耕AI加速领域十余年,专注打造拥有强大通用性、易用性和高性能的通用人工智能芯片,并持续精进在芯片架构、软件栈、工程化系统层级等方面的技术实力。目前,昆仑芯科技已实现两代通用AI芯片产品的量产及落地应用,通过用算力赋能不同场景中的 AI 应用,驱动千行百业的智能化转型。
为进一步降本增效以及提升用户体验,vivo AI工程中心同步启动AI多元算力项目,联合昆仑芯科技,在语音识别场景首先展开研发共建,深入合作,并已取得阶段性突破进展。
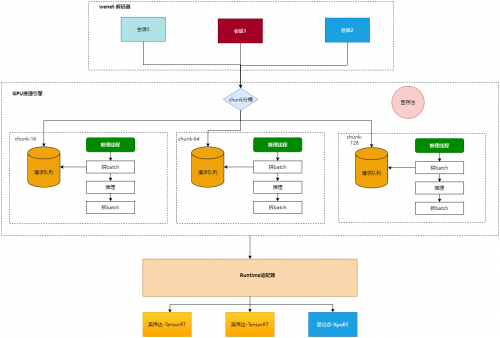
vivo自研语音识别流式推理引擎
整个引擎包括四部分:
1.wenet解码器,包括前端处理(特征、VAD等)->encoder->语言模型(wfst)->decoder流程;
2.数据调度,动态batching、分桶排序等;
3..Runtime适配层,抽象模型推理接口,便于适配不同推理后端;
4.Runtime层,后端推理层包括onnxruntime、GPU、昆仑芯的XpuRT等。
自研引擎特点:
支持多batch流式请求,多batch能充分发挥硬件计算性能;
动态batchting,根据实际请求会在一定时间自动组装batch,便于提升引擎的并发吞吐能力;
分桶排序,减少多batch的无效padding,减少无效计算量;
显存池,高并发下流式识别缓存会频繁申请和释放,通过显存池优化了这部分开销,提高性能。
另外针对语言模型(wfst)优化:
语言模型的lattice-faster-decoder过程有千万/秒的小对象内存申请(ForwardLink和BackpointerToken),通过将小对象合并大对象的池化方案,一次wfst的search从14ms减少到5ms;
线程模型优化。默认的线程模型是一个会话一个pthread线程,在GPU方案中,每秒数千线程创建系统负载较大,通过将pthread线程优化为bthread;
对象复用。将AsrDecoder池化复用,减少内存的动态申请,cpu性能提升27%。
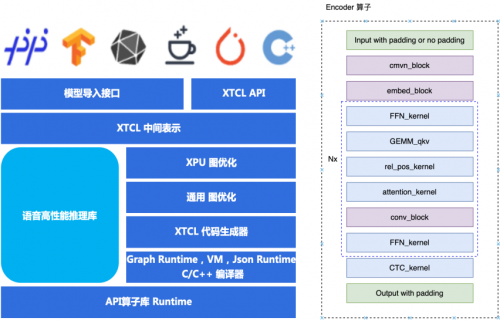
昆仑芯高性能推理库方案
AI推理引擎面临的最大技术挑战——同时满足业务快速灵活迭代和硬件高性能。面对该挑战,昆仑芯科技团队为vivo提供了两种解决方案:基于图编译引擎方案和基于高性能推理库方案。综合业务和性能的双重考量,vivo团队最终选择了高性能推理库方案。该方案基于昆仑芯API高性能算子库自研模型推理大算子,主要由Encocer和Decoder两个大算子组成。
高性能推理库特点:
支持动态shape,性能与静态shape无异,相比”静态模拟动态“可节省大量宝贵的显存资源;
支持多batch流式推理,解决流式推理一大难题,特别是cache管理;
深度图优化,使用了昆仑芯丰富的图融合优化,如:ffn_kernel_fusion、attention_fusion等,可变长优化技术等;
不同量化策略,FP16/INT8动态静态量化以及混合量化;
定制算子融合,如ConforermEncoder的RelPos相关计算可以融合为rel_pos_fusion_kernel等;
自动化工具,模型一键导入等。
性能测试
对比不同后端的性能数据onnxruntime(cpu)、165w GPU、昆仑芯XPU。
硬件配置:


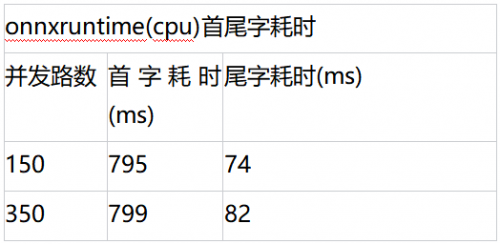
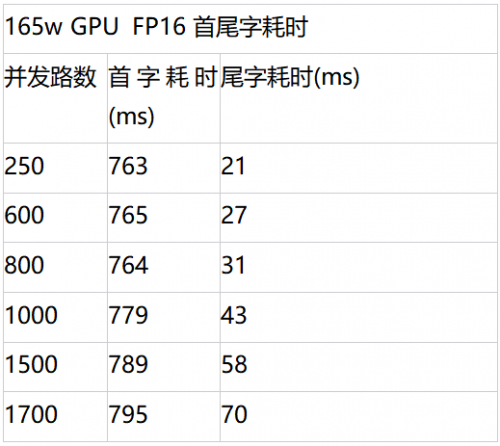

整体来看,在FP16量化后不同后端均达到精度无损,昆仑芯高性能推理库方案单卡并发达到了1400路,相比CPU的350路的最大并发,性能提升约4倍,首字和尾字耗时也大大降低,降本增效明显。单机单卡的测试外,也进行了单机4卡的压测,单机4卡GPU和4卡R200均达到了4000路并发。
相对主流165w GPU方案,昆仑芯语音识别高性能推理库方案通过构建大算子的方式也为业务根据自身特性做针对性融合、量化、裁剪提供了更加便捷、更加有用的工具。
昆仑芯在wenet中开源XPU支持
wenet是国内最大的语音开源社区,致力于推动语音技术落地, “共创共赢”。昆仑芯是wenet中支持的首款新型异构AI推理芯片,基于昆仑芯第二代推理卡模型推理采用语音高性能推理库的非流式解码方案,目前源码已合入到wenet主线。第二阶段,昆仑芯、vivo、wenet社区三方联手,将共同推出图引擎和高性能库两种后端推理,支持多batch流式解码,模型优化到部署端到端的解决方案,为客户业务落地持续赋能。
未来,昆仑芯将持续发挥在推理生态的领先优势,助力语音业务用户体验不断优化,同时也将与社区紧密合作,协力共建wenet国产生态。
文章来源:网络 相关文章
相关文章




 精彩导读
精彩导读






 热门资讯
热门资讯 关注我们
关注我们
